Description
|
|
Created by Yuven Niccls
7 months ago
|
|
Page 1
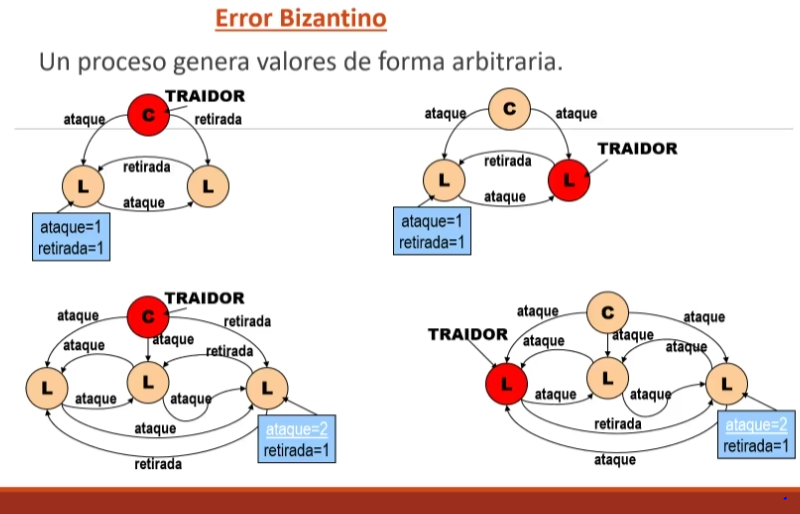
Concepto de los modelos de fallos: -TIPOS DE FALLOS CONTINUANDO LOS CONCEPTOS TENEMOS LOS FALLOS ARBRITARIOS: Los fallos arbitrarios, también conocidos como fallos bizantinos (Byzantine Failures), son uno de los tipos de fallos más complejos y difíciles de manejar en los sistemas distribuidos. Este tipo de fallo ocurre cuando un componente del sistema (un proceso, nodo o red) se comporta de manera impredecible o maliciosa, enviando información incorrecta, inconsistente o engañosa a otros componentes del sistema. A diferencia de los fallos por parada (crash failures) o los fallos por omisión (omission failures), los fallos arbitrarios no siguen un patrón predecible, lo que los hace especialmente desafiantes. Estrategias para Manejar Fallos Arbitrarios Algoritmos de consenso tolerantes a fallos bizantinos: Algoritmo de Paxos Bizantino (Byzantine Paxos): Extensión del algoritmo Paxos para manejar fallos bizantinos. Algoritmo PBFT (Practical Byzantine Fault Tolerance): Un algoritmo práctico para lograr consenso en sistemas con fallos bizantinos. Blockchain y consenso en criptomonedas: Algoritmos como Proof of Work (PoW) o Proof of Stake (PoS) están diseñados para tolerar fallos bizantinos en redes descentralizadas. Replicación de estado: Replicar el estado del sistema en múltiples nodos para asegurar que, incluso si algunos nodos fallan arbitrariamente, el sistema pueda seguir funcionando correctamente. Verificación y validación: Implementar mecanismos para verificar la autenticidad e integridad de los mensajes, como firmas digitales o hashes criptográficos. Detección de anomalías: Usar técnicas de monitoreo y detección de comportamientos anómalos para identificar posibles fallos arbitrarios. Redundancia y diversidad: Utilizar múltiples componentes redundantes y diversos (por ejemplo, diferentes implementaciones de software) para reducir la probabilidad de que todos fallen de la misma manera. Ejemplo Práctico: Sistema de Votación Distribuido En un sistema de votación distribuido, un fallo arbitrario podría ocurrir si un nodo malicioso envía votos falsos o altera los votos existentes. Para manejar esto, el sistema podría usar un algoritmo de consenso tolerante a fallos bizantinos para asegurar que todos los nodos acuerden el resultado correcto, incluso si algunos nodos están enviando información incorrecta. En resumen, los fallos arbitrarios son un desafío significativo en los sistemas distribuidos debido a su naturaleza impredecible y potencialmente maliciosa. Sin embargo, con las técnicas adecuadas, como algoritmos de consenso tolerantes a fallos bizantinos y mecanismos de verificación, es posible diseñar sistemas robustos que puedan manejar este tipo de fallos.
{kind=link}
Page 2
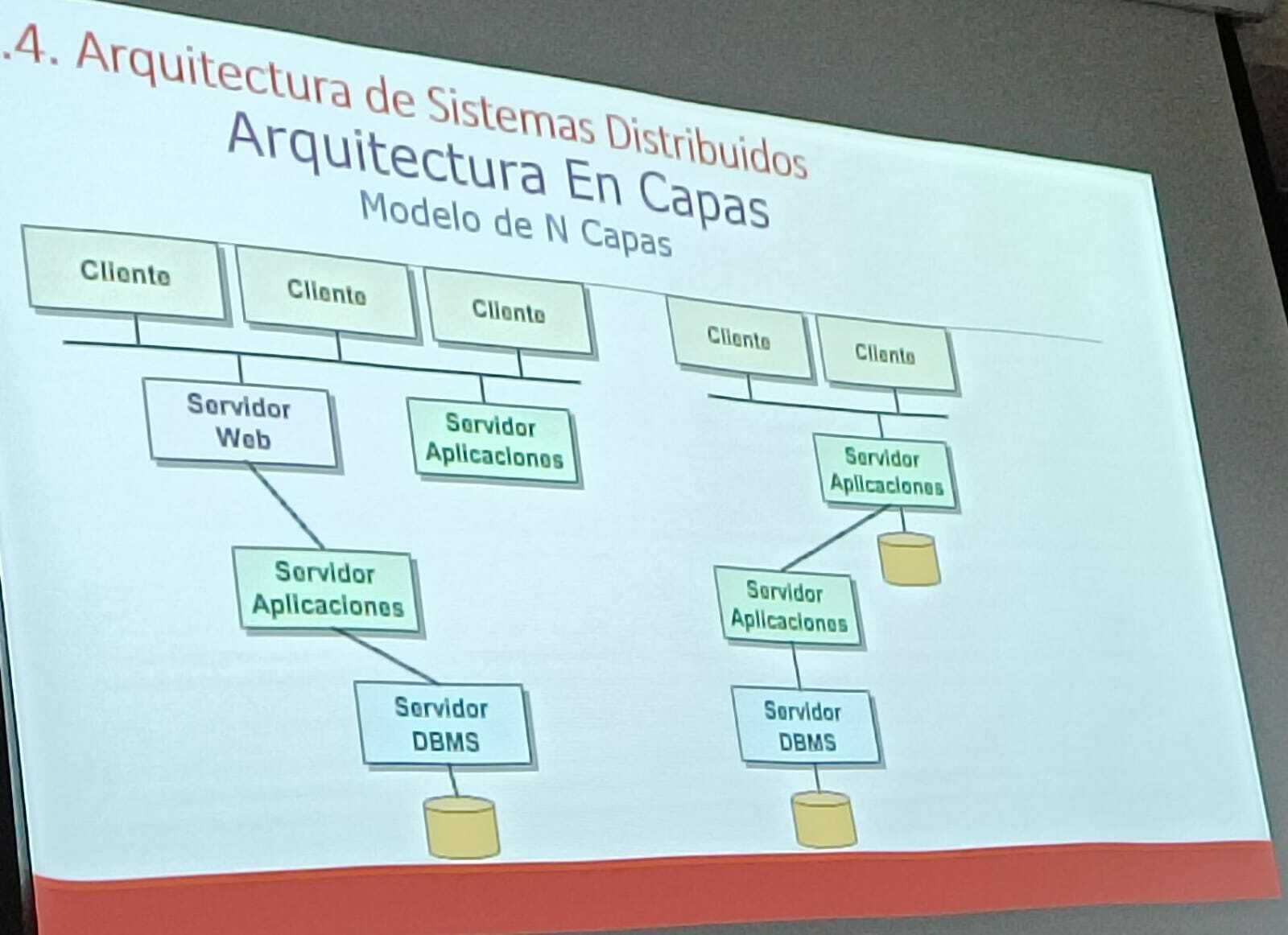
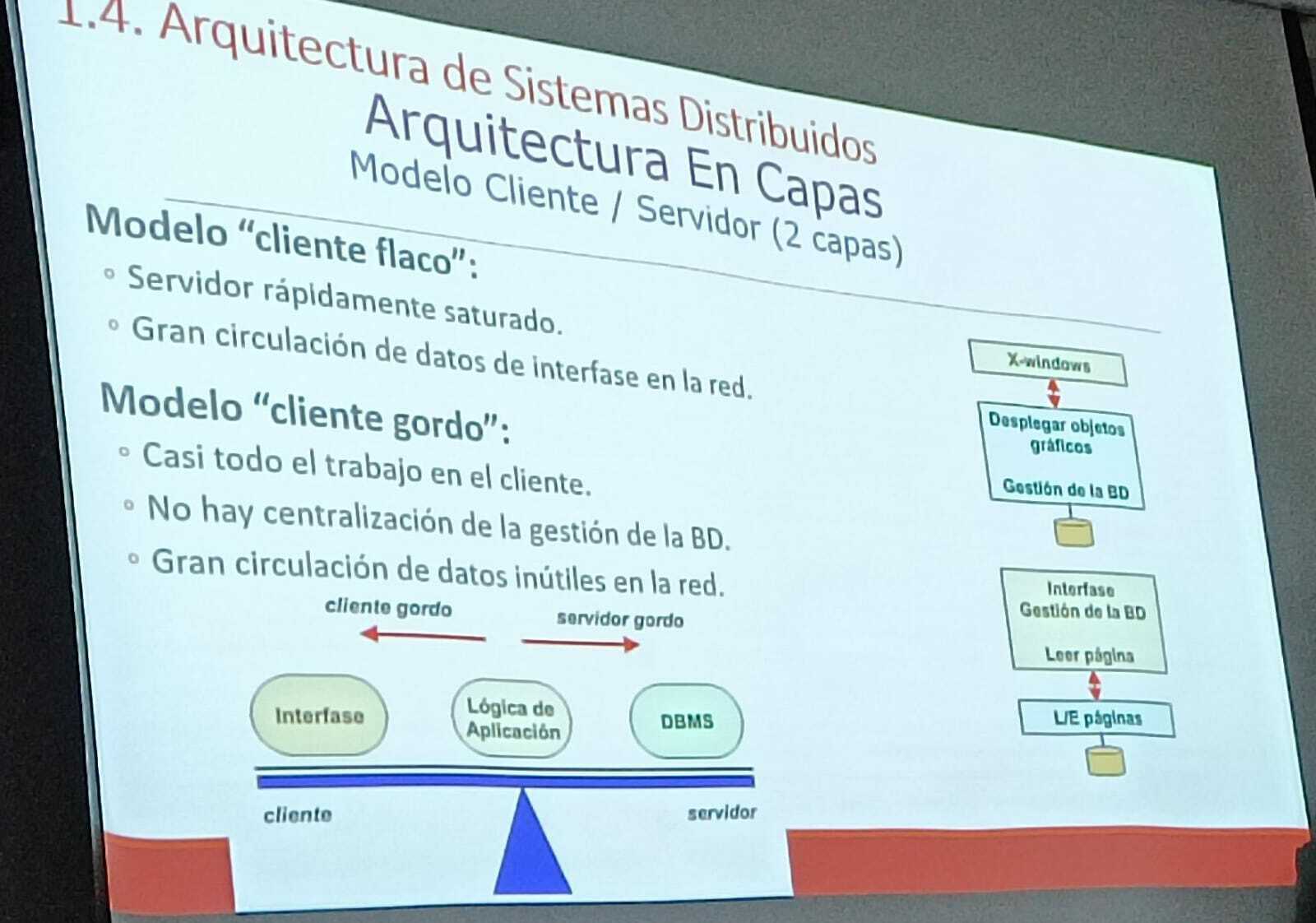
MODELOS DE SISTEMA DISTRIBUIDOS MODELOS DE FALLO, comunicacìon fiable entre dos procesos: DEBE DE Cumplir con dos criterios: VALIDEZ, Es decir que no habra fallos por omision en el canal INTEGRIDAD, no hay fallos bizantinos en el canal "A MENUDO CONSIDERAMOS QUE LA COMUNICACION ES FIABLE PARA CENTRARNOS EN LOS PROBLEMAS DE LOS PROCESOS" ARQUITECTURA DE SISTEMAS DISTRIBUIDOS ARQUITECTURA EN CAPAS, MODELO CLIENTE - SERVIDOR (2 CAPAS) ARQUITECTURA BASADAS EN OBJETOS "MIDDLEWARE" Y EL ODBC : EL LLAMADO ENTRE LA APLICACION Y LA BASE DE DATOS
{kind=link}
Page 3
{kind=link}
Page 4
{kind=link}
Page 5
ACTIVIDAD DE CLASE FECHA:05/03/25 POR: BRAYAN KEVIN ROJAS MAMANI EN ESTA ACTIVIDAD ELIJO LO QUE ES EL MIDDLEWARE DE BASE DATOS, POR QUE? Sobre este middleware se dice que es una capa de software que su función es ser un puente o un intermediario entre la aplicación y una base de datos, ya que permite la conexión permitiendo que la aplicación se comunique con cualquier base de datos. Entre sus características se tiene los siguientes: • Separar los datos sin procesar del front-end, ocultando los detallas de la conexión y el acceso a la base de datos y así permitiendo la interacción con diferentes bases de datos o DBMS. • Sobre las bases de datos que puede acceder están todos los que se conocen actualmente como el MySQL, Oracle, SQL Server, PostgreSQL y sin la necesidad de estar cambiando el código! • Facilita lo que es la migración entre todas las bases de datos que mencione con ningún cambio en el código de la aplicación. • Sobre todo, la seguridad, porque nos ofrece lo que son mecanismos de seguridad para proteger las conexión o conexiones y también los datos, como el cifrado de conexiones y la autenticación. Para concluir, en mi opinión es de que el middleware de base datos es muy interesante y fácil de usar y/o aplicar en algún proyecto que se estén usando diferentes lenguajes de BD oh corrijo, herramientas de base de datos para una aplicación ya que nos facilita la gestión de conexiones y a que sean más seguros. El middleware de bases de datos es esencial en una arquitectura de microservicios, ya que facilita el acceso a los datos de manera eficiente y desacoplada. Ya sea mediante ORMs como Hibernate o Entity Framework, o mediante drivers como JDBC o MongoDB Driver, el middleware permite que los microservicios interactúen con bases de datos sin preocuparse por los detalles técnicos. Esto es clave para construir sistemas escalables, modulares y fáciles de mantener.
Page 6
ARQUITECTURAS BASADAS EN OBJETOS ¿Qué es una Arquitectura Basada en Objetos? Una arquitectura basada en objetos es un modelo de diseño en el que: Los componentes del sistema se representan como objetos. Cada objeto es una instancia de una clase, que define su estructura (atributos) y comportamiento (métodos). Los objetos interactúan entre sí mediante mensajes o llamadas a métodos. Este enfoque es especialmente útil en sistemas complejos, ya que permite organizar el código de manera modular y reutilizable. QUE ES CORBA CORBA (Common Object Request Broker Architecture) Es un estándar de middleware desarrollado por el OMG (Object Management Group) que permite que objetos de software, escritos en diferentes lenguajes de programación y ejecutándose en diferentes plataformas, se comuniquen entre sí en un sistema distribuido. En términos simples, CORBA actúa como un "traductor universal" que permite que aplicaciones heterogéneas (diferentes lenguajes, sistemas operativos o hardware) trabajen juntas. ARQUITECTURA CENTRADAS EN DATOS SE TIENE VARIOS SERVIDORES DE BASE DE DATOS Las consultas y/o operaciones distribuyen en los diferentes sitios y pueden haber varios replicados VENTAJAS: Mayor disponibilidad de datos, distribucion del procesamiento de la base de datos. DESVENTAJA Arquitectura mas compleja (MINIMO 2 BASES DE DATOS), SQL SERVER O MONGO DB
Page 7
ARQUITECTURAS BASADAS EN SERVICOS Conocidas como SOA s un estilo de aquitectura de tecnologias de informacion que permite integrar el negocio como un conjunto de servicios interrelacionados (TAREAS REPETITIVAS DE TRABAJO). CON ACCESO SOLO, a atravez de internet y acceso a los datos que tenian compartidos las organizaciones ya que no permitia mas de una conexion a la vez, para dar solucion a eso se creo web services de ahi nace SOA. ARQUITECTURA BASADAS EN SERVICIOS CICLO DE VIDA ARQUITECTURA BASADAS EN SERVICIOS ENDPOINT Un endpoint es un punto de acceso clave en una API que define cómo los clientes pueden interactuar con un servicio. Está compuesto por una URL, un método HTTP, parámetros y una respuesta. Los endpoints son esenciales para construir sistemas distribuidos y permiten la comunicación entre aplicaciones de manera eficiente y segura. Si necesitas más detalles o ejemplos COMUNICACION ENTRE PROCESOS Comunicación entre Procesos La comunicación entre procesos (IPC, Inter-Process Communication) se refiere a los mecanismos que permiten que dos o más procesos (programas en ejecución) intercambien información. Esto es esencial en sistemas distribuidos, donde los procesos pueden estar ejecutándose en diferentes máquinas. Métodos de Comunicación entre Procesos: Sockets: Permiten la comunicación entre procesos a través de una red. Ejemplo: Un servidor web que se comunica con un navegador. Tuberías (Pipes): Permiten la comunicación entre procesos en la misma máquina. Ejemplo: Un proceso envía datos a otro proceso a través de una tubería. Memoria Compartida: Varios procesos acceden a la misma región de memoria para intercambiar datos. Ejemplo: Dos procesos que comparten datos en un sistema operativo. Colas de Mensajes: Los procesos envían y reciben mensajes a través de una cola. Ejemplo: Un sistema de mensajería entre microservicios. Llamadas a Procedimiento Remoto (RPC): Un proceso invoca una función en otro proceso, como si fuera local. Ejemplo: Un cliente que llama a una función en un servidor remoto.
Modelo OSI El Modelo OSI es un marco de referencia que describe cómo los sistemas se comunican a través de una red. Está dividido en 7 capas, cada una con una función específica. Estas capas permiten entender y estandarizar la comunicación entre dispositivos. Las 7 Capas del Modelo OSI: Capa Física (Capa 1): Se encarga de la transmisión física de los datos (cables, señales eléctricas, etc.). Ejemplo: Cable Ethernet o señal Wi-Fi. Capa de Enlace de Datos (Capa 2): Gestiona la transferencia confiable de datos entre dispositivos en la misma red. Ejemplo: Protocolos como Ethernet o Wi-Fi (MAC). Capa de Red (Capa 3): Encargada del enrutamiento de datos entre redes diferentes. Ejemplo: Protocolo IP (Internet Protocol). Capa de Transporte (Capa 4): Proporciona comunicación confiable entre dispositivos (control de errores, flujo de datos). Ejemplo: Protocolos TCP LENTO PERO SEGURO, SOLO QUE SI SE PERDE EL DATOS TENDRIA QUE RESUBIR EL DATO DE NUEVIO(Transmission Control Protocol) y UDP EJEMPLO LLAMADAS DE WHATTSAP(User Datagram Protocol). Capa de Sesión (Capa 5): Gestiona las sesiones de comunicación entre aplicaciones. Ejemplo: Establecer, mantener y finalizar conexiones. Capa de Presentación (Capa 6): Se encarga de la representación de los datos (codificación, cifrado, compresión). Ejemplo: Convertir datos a formato JSON o XML. Capa de Aplicación (Capa 7): Proporciona servicios directamente a las aplicaciones del usuario. Ejemplo: Protocolos HTTP, FTP, SMTP.
Page 8
12/03/25 COMUNICACION ENTRE PROCESOS CLIENTE- SERVIDOR PROGRAMAS CONCURRENTES PROCESOS CONCURRENTES SINCRONIZACION SINCRONOS Y ASÌNCRONOS
Page 9
ACTIVIDAD DE AUTOAPRENDIZAJE DOCKERS https://learn.microsoft.com/es-es/training/modules/intro-to-docker-containers/2-what-is-docker RESPUESTAS A MAS PROFUNDIDAD, MAS DESARROLLO A CONTINUACION, Comunicacion entre procesos: cuantos puertos de entrada existen en una un servidor conceptos fundamentales que deben de ser considerados par la
Page 10
SEGURIDAD EN SISTEMAS DISTRIBUIDOS Los problemas de seguridad relacionados con los datos en "transito", la tridad de la infromacionm los demas son para la seguridad de la informatica. Mecanismo de seguridad Cifrado, firma, RIESGOS EN SISTEMAS DISTRIBUIDOS EAVESDROPPING - DENIAL OF SERVICE (DENEGACION DE SERVICIO) SIMETRICA ASIMETRICA CRIPTOGRAFIA DATA ENCRYPTION STANDARD DES 3DES, AES , CIFRADOS DE FLUJO ESTEGANOGRAFIA
Page 11
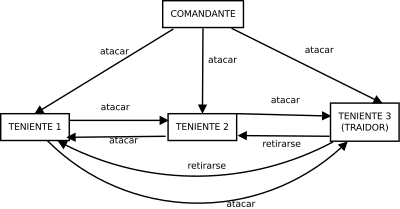
Roba banco: MODELO FISICO MODELO ARQUITECTONICO MODELO DE INTERACCION MODELO DE FALLOS que es el crowourcing
Page 12
UNIDAD 2 SINCRONIZACION DE PROCESOS DISTRIBUIDOS INTRODUCCION FORMA DE IMPLANATAR LAS REGIONES CRITICAS: DEFINIR UNA REGION CRITICA, ASIGNAR RECURSOS EN UN SISTEMA DISTRIBUIDOS EXCLUCION MUTUA Y LA SINCRONIZACION, RELOJES EVENTOS Y ESTADOS SINCRONIZAR, consiste en garantizar que los procesos se ejecuten en forma cronologica y a la misma vez respetar el orden de los eventos dentro del sistema. sincronizacion de relojes, generalmente los algoritmos tienen las propiedades, sobre la informacion mas relevante se distribuye entre varias maquinas ya que los procesos toman las decisiones solo con base en la informacion disponible en fprma local pero debe evitarse un unico punto de fallo en el sistema y no existe un relog comun o alguna otra fuente precis del tiempo global SINCRONIZACION DE RELOJES En un sistema centralizado el tiempo no es ambiguo, en un sistema distribuido no es trivial poenerse deacuerdo a todas las maquinas en sincronizar todopara esto se requiere un acuerdo global con el tiempo, la pregunta si es possible sincronzsar en un sistema distribuido osea si se puede RELOGES LOGICOS estan relacionados a los relojes FISICOS, os relojes son piezas de cuarzo que estan inscrutados en nuestras maquinas a eso nos da la hora en cada dispositivo que tenemos eso representa los reloges fisicos. Se manejan con dos tipo de registros los contadores y los mantenedor, ESTADODS GLOBALES Y CORTES CONCISTENTES CONSENSO Y PROBLEMAS RELACIONADOS CONSENSO EN SISTEMAS SINCRONOS Y ASINCRONOS
Page 13
OTROS ALGORITMOS
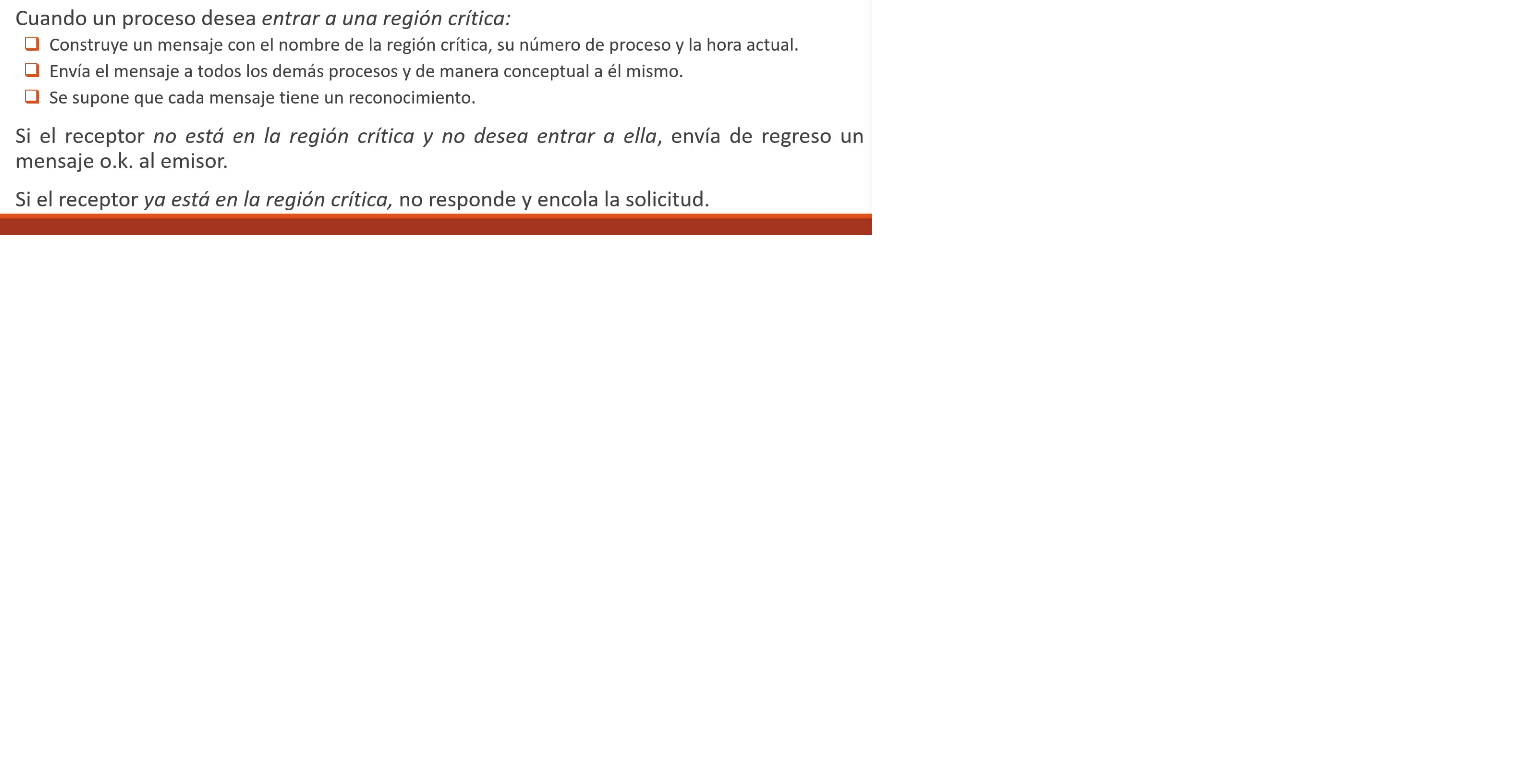
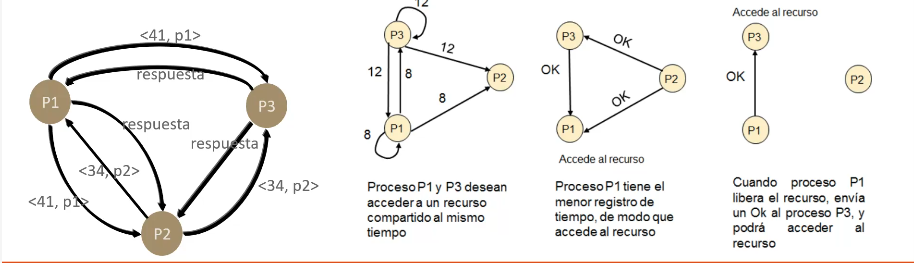
RELOJES EVENTOS Y ESTADOS El algoritmo distribuido, de exclucion El objetivo es no tener un unico punto de fallo osea que el coordinador central. Algoritmo de lamport mejorado que se requiere un orden totoal de todos los eventos en el sistema para saber cual ocurrio primero. cuando un procesos desea entrar a una REGION CRITICAS que se atiene de uno a uno y no de manera simultanea la exclusion murua queda garantizada sin bloqueo ni inanicion el numero de mensajes nesesarios por entrada es 2(n-1) siendo n el numero total de procesos total de procesos en el sistema. No existe un unico punto de fallo sino N Se incrementa la probabilidad de fallo en N veces y tambien el trafico en la red se puede solucionar el bloqueo si, el emisor espera y sigue intentando hata que regresa una respuesta o el emisor concluye que el destinatario esta fuera de servicio. otros problemas son que cada procesos debe mantener la lista de miembros del grupo incluyendo los procesos que ingresan los que salen y los que fallan
{kind=link}
{kind=link}
{kind=link}
EL ALGORITMO TOKEN RING Los procesos se organizan por software formando un anillo logico asigandose a cada proceso una posicion en el anillo. El algoritmo Token Ring es un protocolo de red que permite a las computadoras enviar datos en una red de área local (LAN).
{kind=link}
En un instante dado solo un procesos este puede estar un una region critica ya que si la ficha se pierde tiene que regenerarse ero es muy dificl detectar su perdidad. como se puede regenerar? la ficha?, entonces uno de ellos dira tengo que regenrar la ficha el cual sera el ultimo procesos el cual haya usado una region critica de manera correcta. todos los procesos deben mantener la configuracion actual del anillo.
ALGORITMOS DE ELECCION ALGORITMO DEL GRANDULON ES EL QUE TIENE EL MAYOR NUMERO SE VUELVE EN COORDINADOR ALGORITMO DEL ANILLO
{kind=link}
TRANSACCION ATOMICA Las tecnincas de sincronizacion ya vistas son de bajo nivel el programador debe enfretarse directamente con los detalles de la exclusion mutua, el manejor de las regiones criticas, la prevencion de bloqueos, la recuperacion de fallas. Se precisan para tecnincas de abstraccion de mayor nivel que: oculten estos aspectos tecnicos, que permitan a los programadores concentrarse en los lgoritmos y la forma en que los proceso trabajan juntos en paralelo TAL ABSTRACCION LA LLAMEREMOS TRANSACCION ATOMMICA
{kind=link}
EVENTOS Y ESTADOS - BLOQUEOS IGNORAR EL PROBLEMA, DETECCION, PREVENCION, EVITARL LOS BLOQUEOS MEDIANTE LA ASIGANCION CUIDADOSA DE LOS RECURSOS. AVESTRUZ,PRETENDER DE QUE NO PASO NADA PERO, QUE EL PROBLEMA ES IGNORADO. DETECCION DISTRIBUIDA DE BLOQUEOS, DETECTAMOS EL PROCESO Y LO CERRAMOS, TRANSACCION ATOMICAS EJ SE RESUELVE IR ELIMINANDO UNO O MAS TRANSACIONES QUE VAYAN Y QUE ESTEN CONSUMIENDO EL TIEMPO. PREVENCION DE BLOQUEOS, SE TIENE QUE LPREVENCION CONSISTE EN EL DISEÑO CUIDADOSO DEL SISTEMA PARA QUE LOS BOQUEOS SEAN ESTRUCTURALMENTE
{kind=link}
Page 14
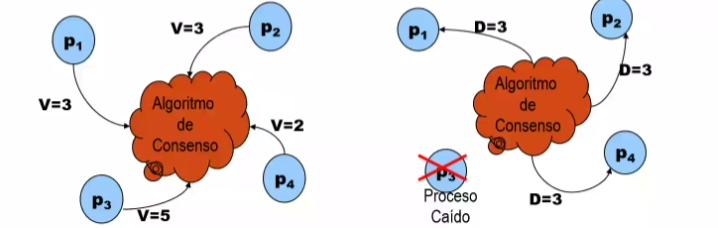
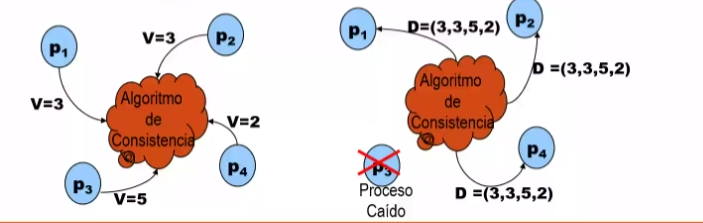
CONSEO Y PROBLEMAS RELACIONADOS EXISTEN TRES TIPOS DE ACTORES: PROPONENTES, ACEPTANTES, APRENDICES Y POR LO GENERAL SUELEN TENERL LOS SIGUIENTES PASOS ELECCION, VOTACION, DECISION LA MAYORIA DE LOS ALGORITMOS DE CONSENSO SIGUEN LA ESTRUCTURA Y LOS PASOS MSOTRADOS PERO ALGUNOS DE ELLOS INTRODUCEN EL CONSESNSO ESTA PRESENTE EN TAREAS EN LAS CUALES VARIOS PROCESOS DEBEN PONERSE DE ACUERDO EN UN VALOR U OPERACION A REALIZAR PROBLEMAS DE CONSENSO GENERAL, CONSISTENCIA INTERACTIVA, PROBLEMA DE LOS GENERALES BIZANTINOS PROBLEMA DE CONSENSO GENERAL CONDICIONES: ACUERDO, EL VALOR DECIDIDO ES IGUAL PARA TODOS LOS PROCESOS CORRECTOS VALIDEZ SI TODOS LOS PROCESOS CORRECTOS ELIGEN EL MISMO VALOR ENTONCES DICHO VALOR SERA EL VALIDO TERMINACION CADA PROCESO CORRECTO FIJA UN VALOR
{kind=link}
{kind=link}
{kind=link}
CONSENSO GENERAL EN UN SSITEMA ASINCRONO LAS RESPUESTAS ES NO, ENTORNO ASINCRONO DEBEMOS ELEJIR DOS DE LAS 3 CARACTERISTICAS SEGURDAD, TERMINACION EXISTSA, TOLERANTE A FALLOS.
Page 15
Arquitectura para grandes volumenes de datos: Big data: sabiduria, conocimiento, informacion,datos, grafico de una piramide base ded atos analiticas no solo genrea infromacion si no que tambien conocimiento si no buscar prtrones o comportamientos, y asi geenerar al aplicacion mental osea una aplicacion cognitivaque vera mas alla que la simple infromacion como tal, los sistemas analiticos , las bd analiticas, power by id , son sistemas que nos permitiran generar conimiento.
FUENTES DE DATOS: estructurados. semi estructurados, No estructurados Estructurados: relatio y legacy databases, spreed sheets, fiat files with, proper recard formats, Semi estructurados: XML, EDI documents No estructurados: web, e mails, multimedia, rss feeds mesaages Y ENTRE EL NO ESTRUCTURADOS ESTAN: ESTATICOS INTERNAL tiempo real, noticias en tienmpo real, precios de mercados, tendencias, predicciones , proyecciones, en tiempo real. CLASIFICACION DE FALLAS: fallas crash se habla de falas que se dan repentinamente, por fallas en el equipo, puede recuperrasse de forma natural o rapida es una falla reversible, como que alguien halla apagado la luz se puede volver a operar, se toman en cuenta en dos escenarios asincornos o sincornos en el modelo asincrono, las fallos carh no se pueden detectar, no hay limitaciones en velocidad de procesamiento, retardos en transmicion, de mensajes de mensajes de deriva de los relogespara detectarlos estam los her bits fallas por omision fallas transitorias pueden darse en cualquier momentos, como sobrecrga de energia o rayos etc, pero puede hacer que este genere un efecto bueno en el ssistema bueno o en el compeonente, los permamanetes, estas fallas son defectos fisicos, o por un masl diseño en el sistema un diseño incorrecto hace que la falla sea no recuperable, intermitente, un diseño incorrecto que pueden dar calores esperados o tambien dar valores que no esperamos, por lo tanto se llama fallas intermitenes, falla transitorio es quwe el entorno esta inestable como erroresque botan nifromcion qe no son coherenyes, error del oprador, no inflijen en falla como tal en e sistema, si no un error de concepcion por el humanos. fallas bizantinas fallas de software que son , por ejemplo codificacion de errores o humanos perdidad de memorias, errores humanos, errores de diseño de software, perdidas de memoria fallas temporales
Page 16
REPLICACION DE BASE DE DATOS, publicador n servidor de base de datos y un distribuidor, agentes de replicacion AGENTES,D E INSTANTANEA, DISTRIBUCION, LECTOR DEL REGRISTRO, LECTOR DE COLA, MEZCLA USAR DOS BASES DE DATOS PA LA REPLICACION. UN SQL EN UN CONTENDOR
Page 17
Tipos de inconsistencias, en replicacion de base de datos: Concistencia de replicacion: referesas el cache, mandar paramtros desde el backend para que lo refresce por cada cambio o varias manera sde eveitar la incosnitencia del cache, algoritmo de sincronizacion. con el tema de los reloges MODELOS DE CONSISTENCIA: centrada en los datos, que son las regiones criticas: son regiones de un sistema que se hacen una operacion a la vez, no dos o mas procesos al mismo tiempo. Modelos centradops en los clientes, que no realiza mucha axtualizaion en el sistema.
Page 18
Arquitecturas descentralizadas, No estructuradas ejemplos dwe gnutella estructuradas, hace que las consultas sean mas eficases, como ejemplo se tiene redes superpuestas estructuradas, choro, tapestru pastrydemilia o viceroy. hibridas, soluciona problemas que no se pueden resolver de modo eficiente ninguno de los modelos anteriores. El blovk chan, qeue nos permite guaradar informacion mediante bloques y añadimos informacion que nos permite las lineas temporales. nodo que eliniemos no nos gener problemas y tampoco u corte abruto de la info que se maneja, que es uba base de datos distribuida sugeridad por satoshi nakamoto - articuilo 2008, n sistema de dinero en efectivo electronico peer to peer- y el bitcoin nace en 2009 Beneficios clave de la blockchain: Mayor transparencia y confianza: La blockchain permite compartir información de forma segura y transparente, lo que aumenta la confianza entre las partes involucradas. Seguridad mejorada: La criptografía y la descentralización hacen que la blockchain sea muy resistente a la manipulación y a la piratería. Trazabilidad y visibilidad: La blockchain facilita el seguimiento de productos y procesos a lo largo de toda la cadena de suministro, lo que mejora la eficiencia y reduce el riesgo de fraudes. Ahorro de costos: La eliminación de intermediarios y la automatización de procesos reducen los costos de transacción y operación. Velocidad y eficiencia: Las transacciones en blockchain pueden ser más rápidas y eficientes que los procesos tradicionales, especialmente en áreas como el comercio y las finanzas. Automatización y contratos inteligentes: La blockchain permite la creación de contratos inteligentes que se ejecutan automáticamente cuando se cumplen las condiciones, lo que agiliza y mejora los procesos. Verificación de identidad: La blockchain puede ser utilizada para crear identidades digitales seguras y verificables, lo que facilita el acceso a servicios y reduce el riesgo de fraude. Detección de fraude: La blockchain ayuda a detectar casos de fraude mediante la verificación de transacciones y la imposibilidad de manipular los registros, según Grant Thornton. Inmutabilidad: Una vez que una transacción se registra en la blockchain, no se puede modificar ni eliminar, lo que garantiza la integridad de la información. Beneficios clave de la blockchain: Mayor transparencia y confianza: La blockchain permite compartir información de forma segura y transparente, lo que aumenta la confianza entre las partes involucradas. Seguridad mejorada: La criptografía y la descentralización hacen que la blockchain sea muy resistente a la manipulación y a la piratería. Trazabilidad y visibilidad: La blockchain facilita el seguimiento de productos y procesos a lo largo de toda la cadena de suministro, lo que mejora la eficiencia y reduce el riesgo de fraudes. Ahorro de costos: La eliminación de intermediarios y la automatización de procesos reducen los costos de transacción y operación. Velocidad y eficiencia: Las transacciones en blockchain pueden ser más rápidas y eficientes que los procesos tradicionales, especialmente en áreas como el comercio y las finanzas. Automatización y contratos inteligentes: La blockchain permite la creación de contratos inteligentes que se ejecutan automáticamente cuando se cumplen las condiciones, lo que agiliza y mejora los procesos. Verificación de identidad: La blockchain puede ser utilizada para crear identidades digitales seguras y verificables, lo que facilita el acceso a servicios y reduce el riesgo de fraude. Detección de fraude: La blockchain ayuda a detectar casos de fraude mediante la verificación de transacciones y la imposibilidad de manipular los registros, según Grant Thornton. Inmutabilidad: Una vez que una transacción se registra en la blockchain, no se puede modificar ni eliminar, lo que garantiza la integridad de la información. como funciona el block chain, un uusario realiza n tranmsaccion en block chain, cada tranmsaccion es un bloque CARACTERISTICAS: imparable,accesisble, peero to peer , sstema distribuido, seguridad. abilidad de los datos, democratico. funcionamiento de las block chain, se validad cutan la transaccion se ejcuta y vlida segun los contratos y scripsts la transaccion, son atomicas, es independiente, es inmortal a no ser que este la funcion eliminar programada.
Want to create your own Notes for free with GoConqr? Learn more.