1842151
Description
Flashcards by Luke Vincent, updated more than 1 year ago
|
|
Created by Luke Vincent
almost 11 years ago
|
|
| Question | Answer |
| Tokenisation | converting strings to tokens |
| Segmentation | splitting into sentences |
| Stemming | |
| Lemmatisation | |
| Part-of-speech tagging | label tokens nouns/verbs/adjectives etc |
| phrasal chunking | form phrasal units from tokens, typically refer to enitities and actions |
| Syntactic analysis | hierarchical analyse sentences into components (subject/object/main verb) |
| Semantic analysis | express literal meaning |
| Named entity recognistion | identify type of entity (person/institution/place/time) |
| Reference resolution | link difference references to the same entity |
| Word sense disambiguation | using context to disambiguate use of a word |
| Relation detection | identify and classify relationships between entiities |
| Event detection | identify, classify and temporarily order events |
| Topic identification | identify words/phrases that relate to a topic |
| Text similarity | measure relevance of a document to a query, or of one document to another |
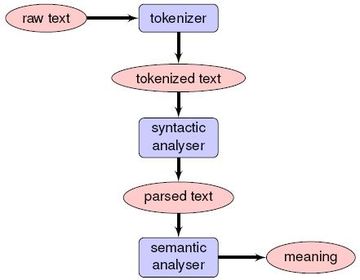
| NLP pipeline | |
| Why is NLP hard? | Many different ways of saying things Hundreds of different dialects Language is used in highly creative ways |
{kind=link}
{kind=link}
{kind=link}
Want to create your own Flashcards for free with GoConqr? Learn more.